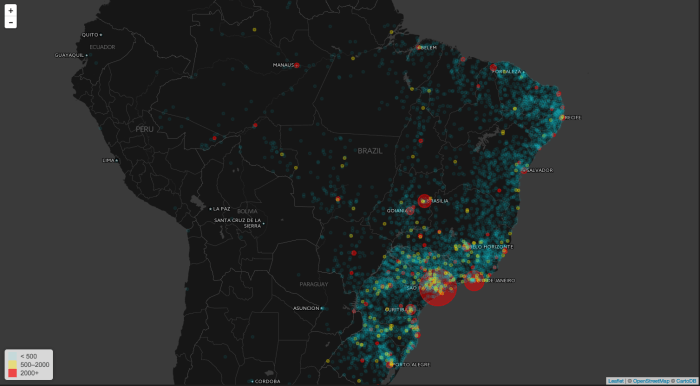
Globo.com, the digital branch of Globo Group, had the rights to do the online live streaming of the FIFA World Cup 2018 for the entire Brazilian national territory.
We already did this in the past and I think that sharing the experience may be useful for the curious minds that want to learn more about the digital live streaming ecosystem as well as for the people interested in how Brazil infrastructure and user’s demand behave in an event with this scale.
Before the event – Road to the world cup
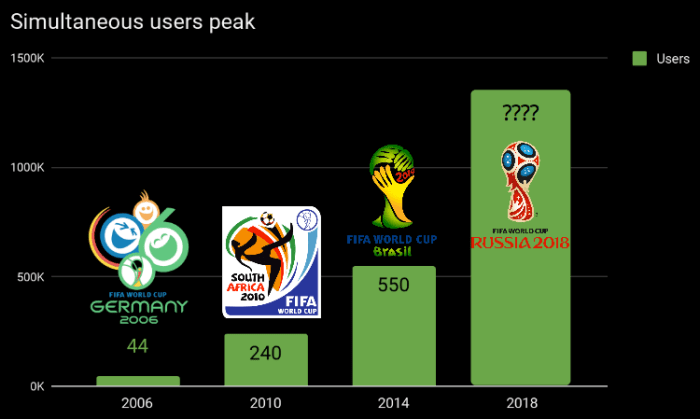
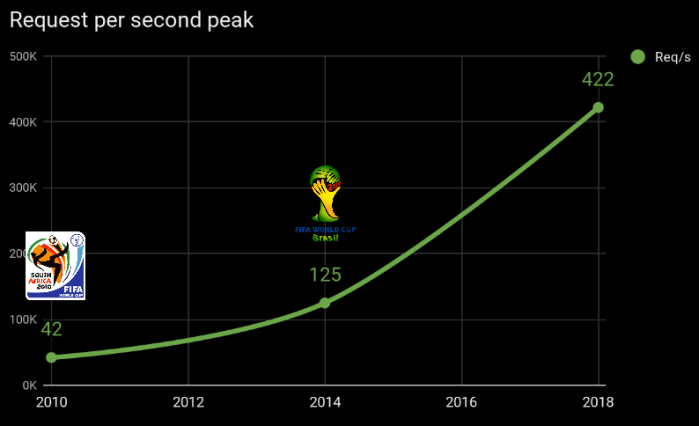
In average, we usually ingest and process about 1TB of video and users fetches around 1PB every single day. Even before the World Cup started, the live stream of a single soccer match had a peak of more than 500K simultaneous users with more than 400k requests per second.
When comparing these numbers to previous events such as the Olympic Games or the FIFA World Cup 2014 we can see an exponential evolution in demand.
Back in 2014, Globo.com CDN was equipped with 20Gbps network interfaces. Now, the nodes were upgraded with 40Gbs, 50Gbs, and 100Gbps NICs. Processors were also upgraded enabling us to deliver 84Gbps on a single machine as part of the preparation for the World Cup.
I’m glad to say that the Linux/kernel fine-tune required was minimal since the newer kernel versions are very well tuned by default.
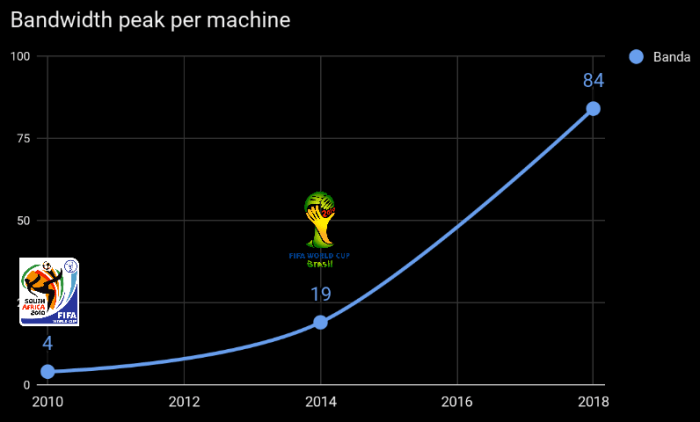
We broke the simultaneous users record set by 2014 FIFA world cup way before the first 2018 World Cup matches. We also noticed an increase in the overall bitrate which likely point that the Internet infrastructure in Brazil improved significally in the past four years.
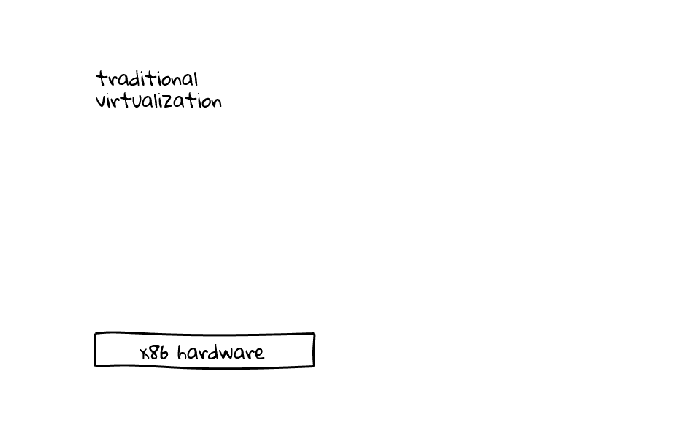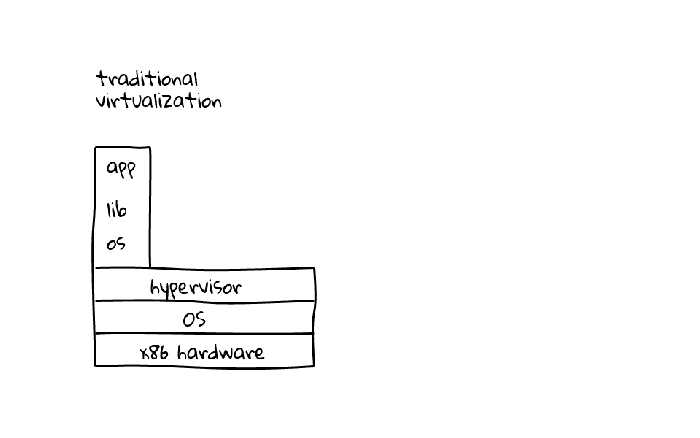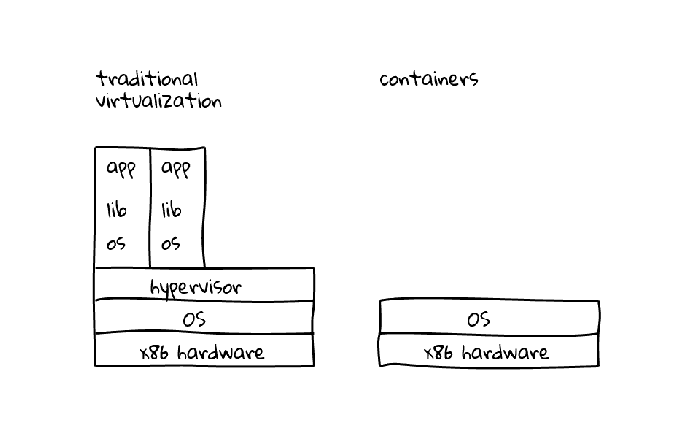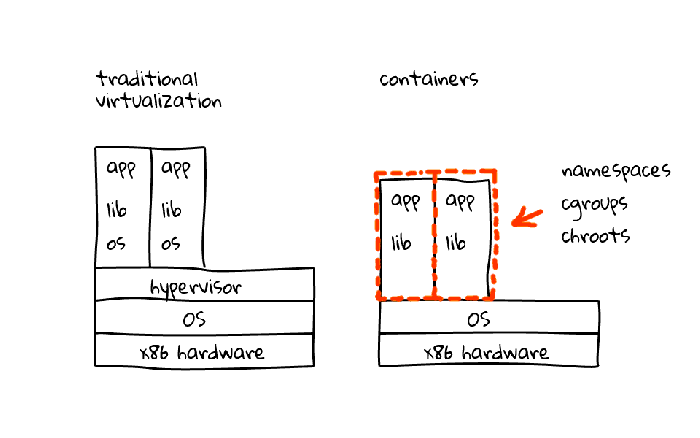
Plataform overview – The strategy 1:1:1
Let’s not focus on the workflow before the video arrives at our ingest encoders. Just think that it’s coming from Russia’s stadiums and reaching our ingest encoders directly. With this simplification in place, we can assume that there are basically two different users of interacting with the video platform: the ones producing the video and others consuming in the other end.
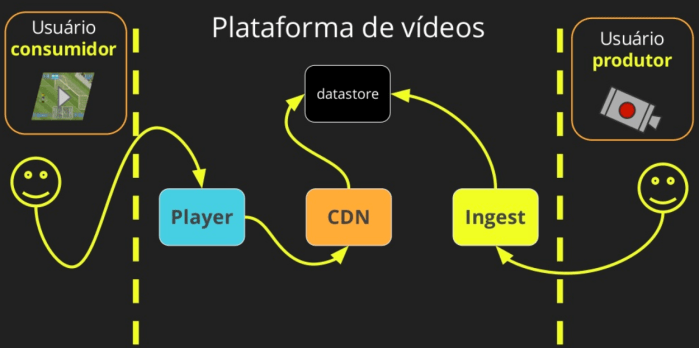
Consumers of the video are the visitors of our internet properties and they watch the live content throughout Globo.com video player, which is responsible for requesting video content to Globo.com’s CDN or one of our CDN partners.
Globo.com player is based on Clappr, an open source HTML5 player that uses hls.js and shaka as its core playback engines.
Globo.com CDN nodes are mostly built on top of OSS projects such as Linux, Nginx (nginx-lua), Lua Programming Language and redis. Our origin is made of multiple ingest points and a mix of solutions such as FFmpeg, Elemental and OBS. A Cassandra cluster is also deployed with the responsibility of storing and manipulating video segments.
OSS projects play a key role in all the initiatives we have within our technology and engineering teams. We also rely a lot on dozens of open source libraries and we try as much as we can to give stuff back to the community.
If you want to know how this architecture works you can learn from the awesome post: Globo.com’s live video platform for the 2014 FIFA World Cup
Constrained by bandwidth – Control the ball
The truth is: the Internet is physically limited, it doesn’t matter if you got more servers, in the end, if a group of users have a link to us of 10Gb/s that’s all we stream to them.
Or we can explore external CDNs more pops but I hope you got the idea! 🙂
In a big event, such as the World Cup, there will be some congestions on the link between our CDN and the final users, how we tackle this problem (of a limited bandwidth) can be divided into three levels:
- OS :: TCP congestion control – the lowest level to control the connection, when it’s saturated, this control is applied to each user.
- Player :: ABR algorithm – it watches metrics such as network speed, CPU load, frame drop among others to decide whether it should adapt to a better or the worst bitrate quality.
- Server :: group bitrate control – when we identify that a group of users, which uses the same link, are using a link that is about to saturate, we can try to help the player to use to a lower bitrate and accommodate more users.
During the event – Goals
Even before the knockout stage, we were able to beat all of our previous records, serving about 1.2M simultaneous users during this match. Our live CDN delivered, at its peak, about 700K requests/s and our worst response time was half a second for a 4 seconds video segment.
Some of our servers were able to reach (peak) 37Gb/s in bandwidth. We also delivered the 4K live streaming using HEVC with a delay of around 25 seconds.
We are constantly evolving the platform and looking at the bleeding edge technologies such as AV1. With the help of the open source community and the growing amount of talents on our technology teams, we hope to keep beating records and delivering the best experience to our users.



You must be logged in to post a comment.