Attention: I released resty-dynacode an openresty library enabling users to add Lua code dynamically to Nginx.
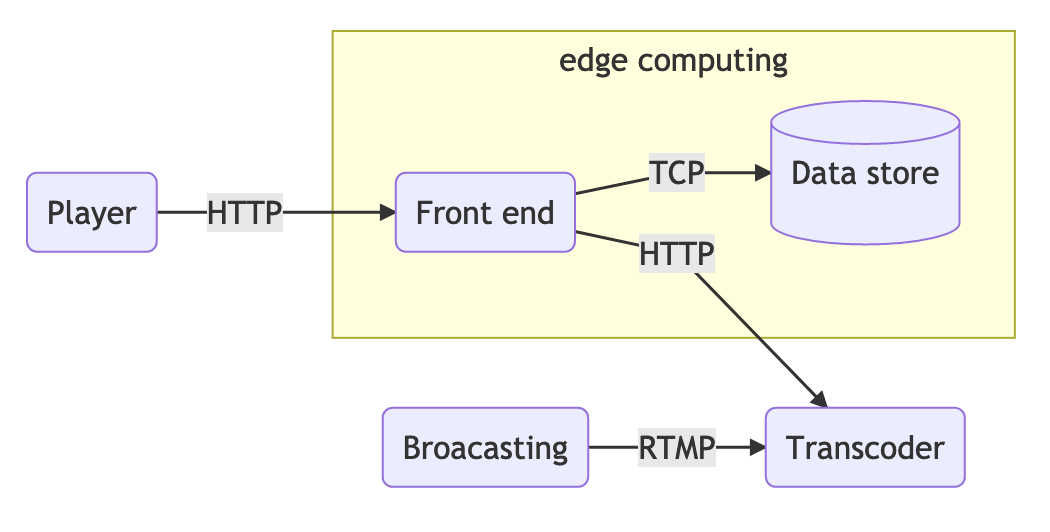
This is the last post in the series, now we’re going to design an edge computing platform using Lua, Nginx, and Redis cluster. Previously, we explained how to add code, not dynamically, in nginx.
Platformize the computations
The platform is meant to provide a way to attach Lua code dynamically into the edge servers. The starting point can be to take the authentication code and port it to this solution.
At the bare minimum, we need a Lua phase name, an identifier and the Lua code. Let’s call this abstraction the computing unit (CU).
If we plan to add a computing unit dynamically to the NOTT, we need to persist it somewhere. A fast data store for this could be Redis.
We also need to find a way to encode the computing unit into some of the Redis data types. What we can do is to use the string to store the computing unit. The key will be the identity and the value will hold the Lua phase and code separated by the string “||“.
The platform needs to know all of the computing units, therefore, we need to list them. We could use the keys command but it can be very slow depending on how much data we have.
A somewhat better solution would be to store all the identities in a set data type, providing an O(N) solution, where N is the number of CUs.
KEYS pattern would also be O(N) however with N being the total number of keys in the data store.
Now that we know how we’re going to encode the computing unit, we need to find a method to parse this string separated by || and also a process to evaluate this string as code in Lua.
To find a proper and safe delimiter is difficult, so we need to make sure that no Lua code or string will ever contain ||.
To split a string we’ll use a function taken from Stackoverflow ![]() and for the code evaluation, Lua offers the loadstring function.
and for the code evaluation, Lua offers the loadstring function.
But now some new questions arise, what happens if the code is syntactically invalid or when the CU raises an error? and how can we deal with these issues?
To deal with syntax errors, we need to validate the returned values from the function loadstring where the first value is the function instance and the last is the error.
And to protect against runtime error, Lua has a builtin function called xpcall (pcall meaning protected call) that receives a function to execute and a second argument which is an error handler function.
With all this in mind, we can develop the core of our platform. Somehow we need to get all the computing units from Redis, parse them to something easier to consume and finally, we can execute the given function.
Before we start to code, we can create a prototype that will replicate the authorization token system we did before but now using Redis to add and fetch the computing unit as well as shielding the platform from broken code.
To test these lines of code, we can go to the terminal and simulate calls to the proper nginx location. Therefore we can understand if the expected behavior is shown.
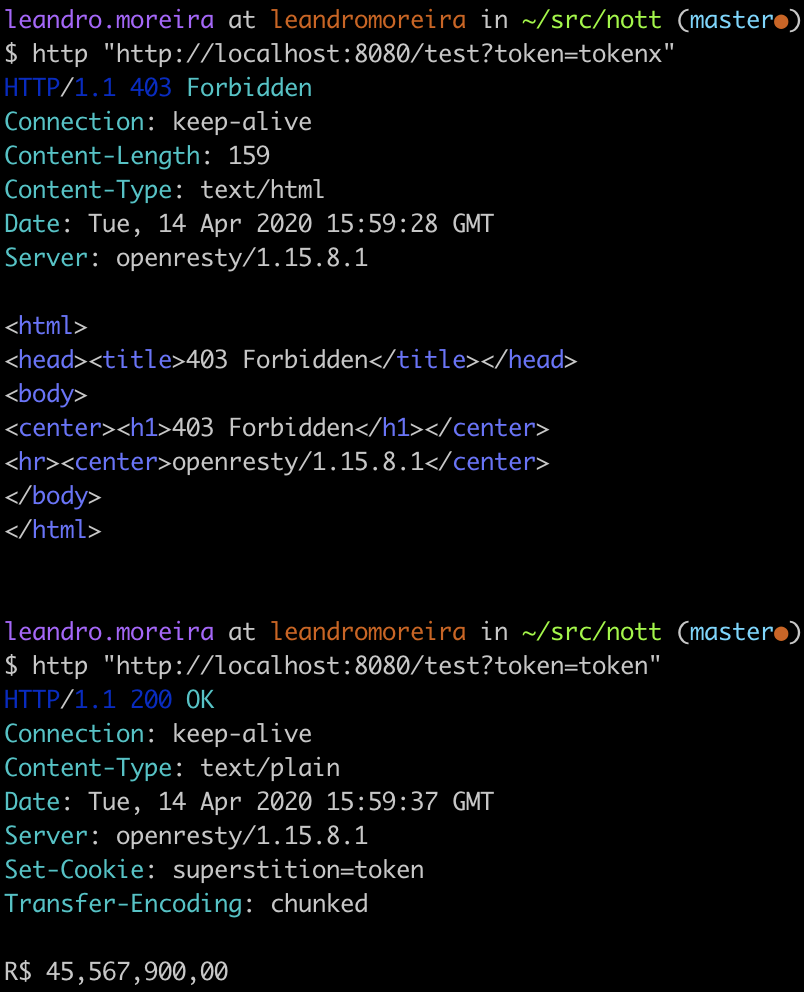
Since we’re comfortable with our experiment, we can start to brainstorm thoughts about the code design and performance trade-offs.
Querying Computer Units
The first decision we can take is about when we’re going to fetch all the computing units (CUs). For the sake of simplicity, we can gather all the CUs for every request but then we’re going to pay extra latency for every client’s request.
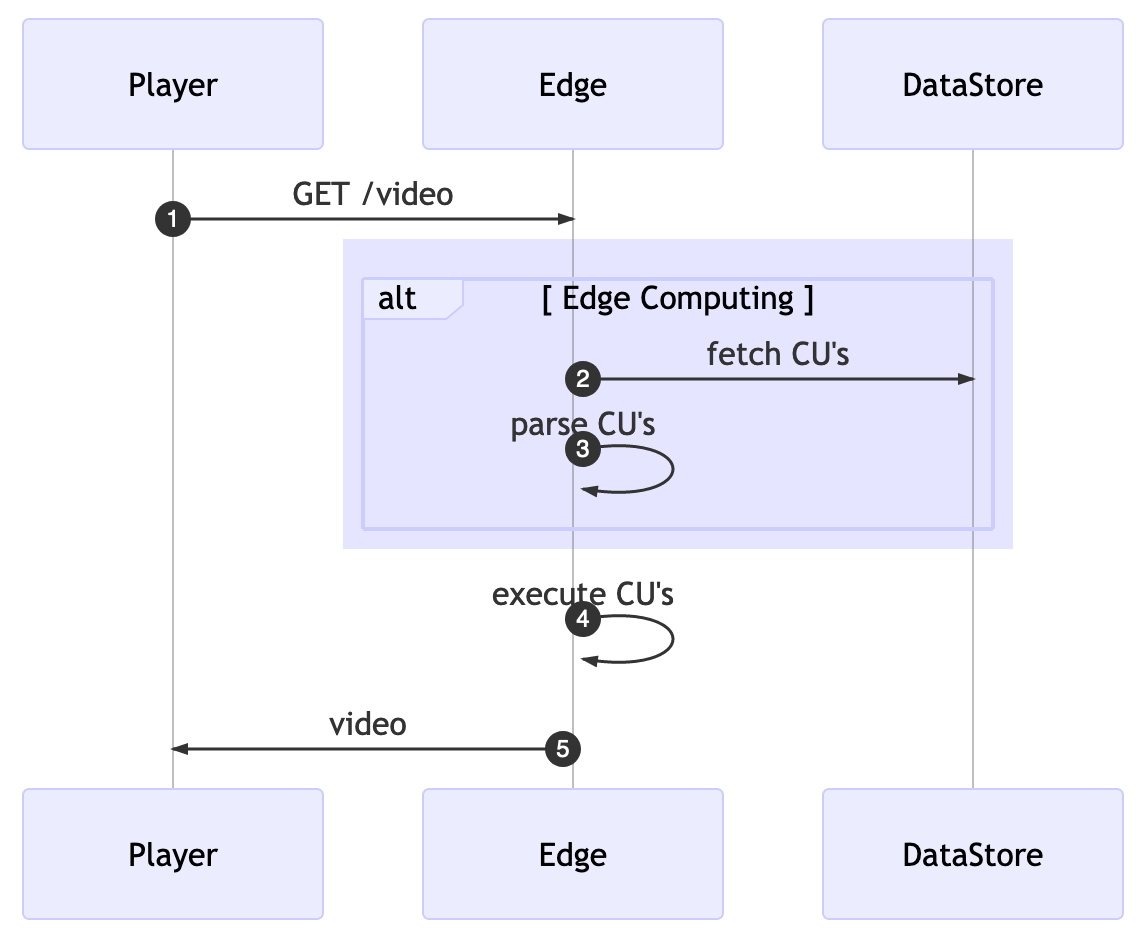
To overcome these challenges, we’ll rely on two known techniques, caching and background processing.
We’ll move the fetch and parse logic to run in the background. With that running periodically, we then store the CUs into a shared memory where the edge computing core can lookup without the need for additional network connections.
Openresty has a function called ngx.timer.every(delay, callback), it runs a callback function every delay seconds in a “light thread” completely detached from the original request. This background job will do the fetch/parser instead of doing so for every request.
Once we got the CUs, we need to find a buffer that our fetcher background function will store them for later execution, openresty offers at least two ways to share data:
- a declared shared memory (lua_shared_dict) with all the Nginx workers
- encapsulate the shared data into a Lua module and use the require function to import the module
The nature of the first option requires software locking. To make it scalable, we need to try to avoid this lock contention.
The Lua module sharing model also requires some care:
“to share changeable data among all the concurrent requests of each Nginx worker, there is must be no nonblocking I/O operations (including ngx.sleep) in the middle of the calculations. As long as you do not give the control back to the Nginx event loop and ngx_lua’s light thread scheduler (even implicitly), there can never be any race conditions in between. “
Edge Computing Bootstrapping
The usage of this edge computing lua library requires you to start the background process and also to explicitly call an execution function for each location and lua phase you want to add it to.
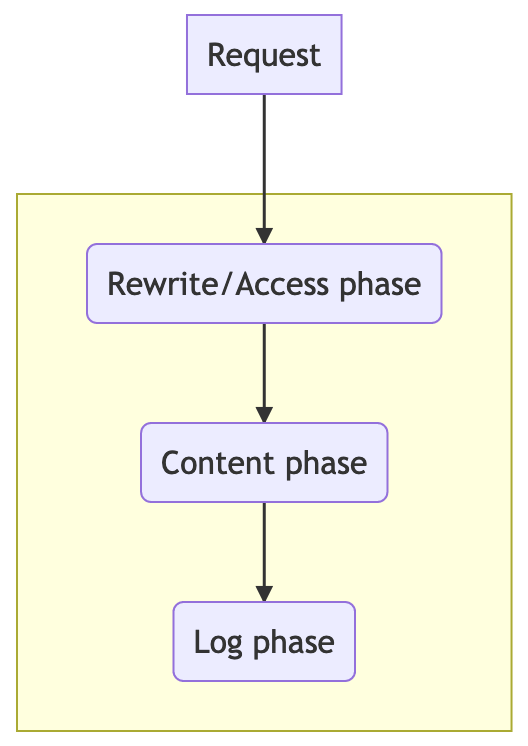
In the past example, we started, on the first request, at the rewrite phase, this will also initiate the background job to update every X seconds.
On the access phase, we’re going to execute the available CUs. If a second request comes in, it’ll “skip” the start and just execute all the cached CUs.
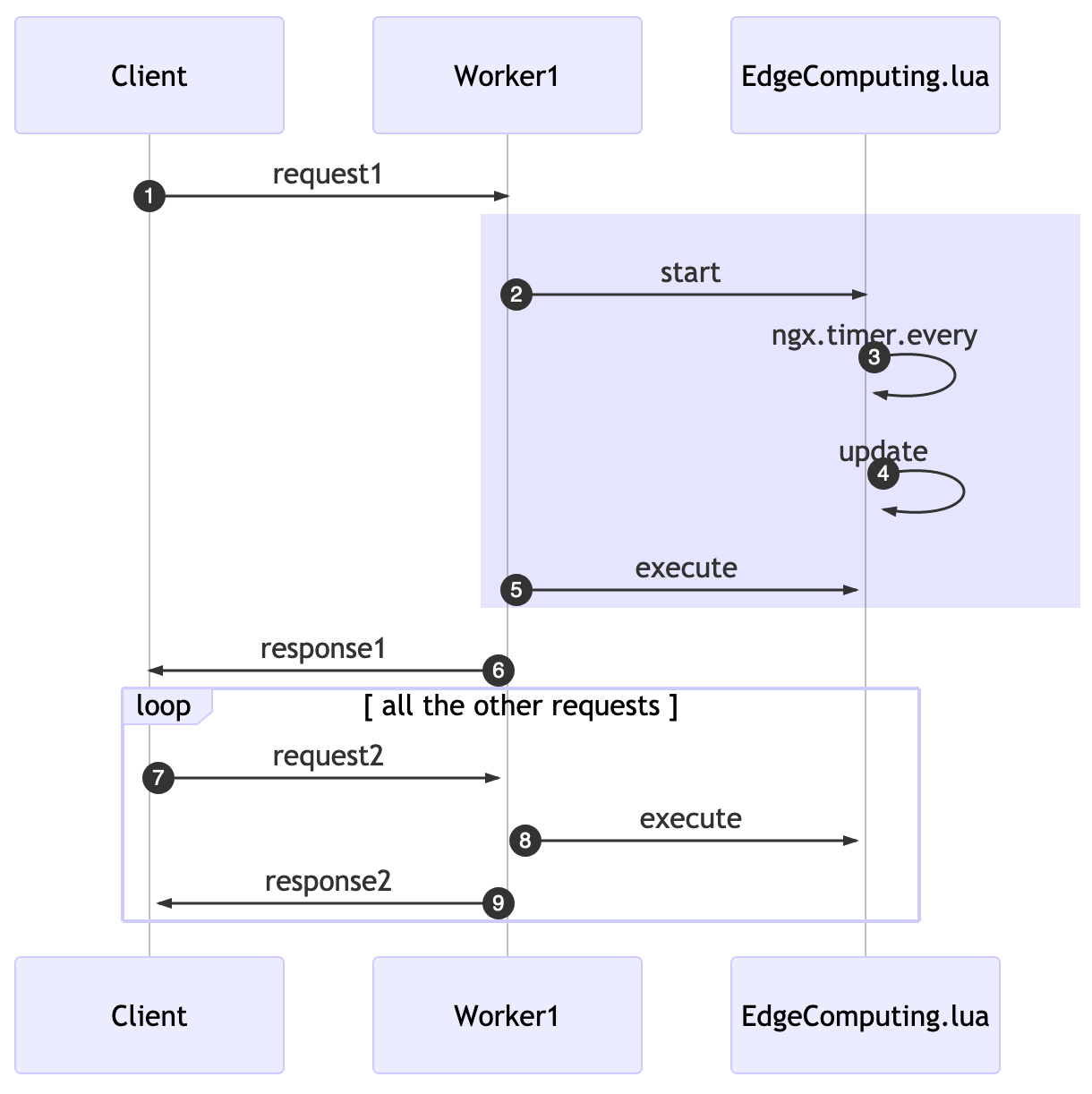
While using these APIs solve our challenge of adding unnecessary latency, it comes at a price: now when we add a new CU to the data store, it might take X seconds to be available for workers.
The rewrite_by_lua_block was used because it’s the first phase where we can start a background job that can access cosockets and works with lua-resty-lock (a library used by resty-redis-cluster).
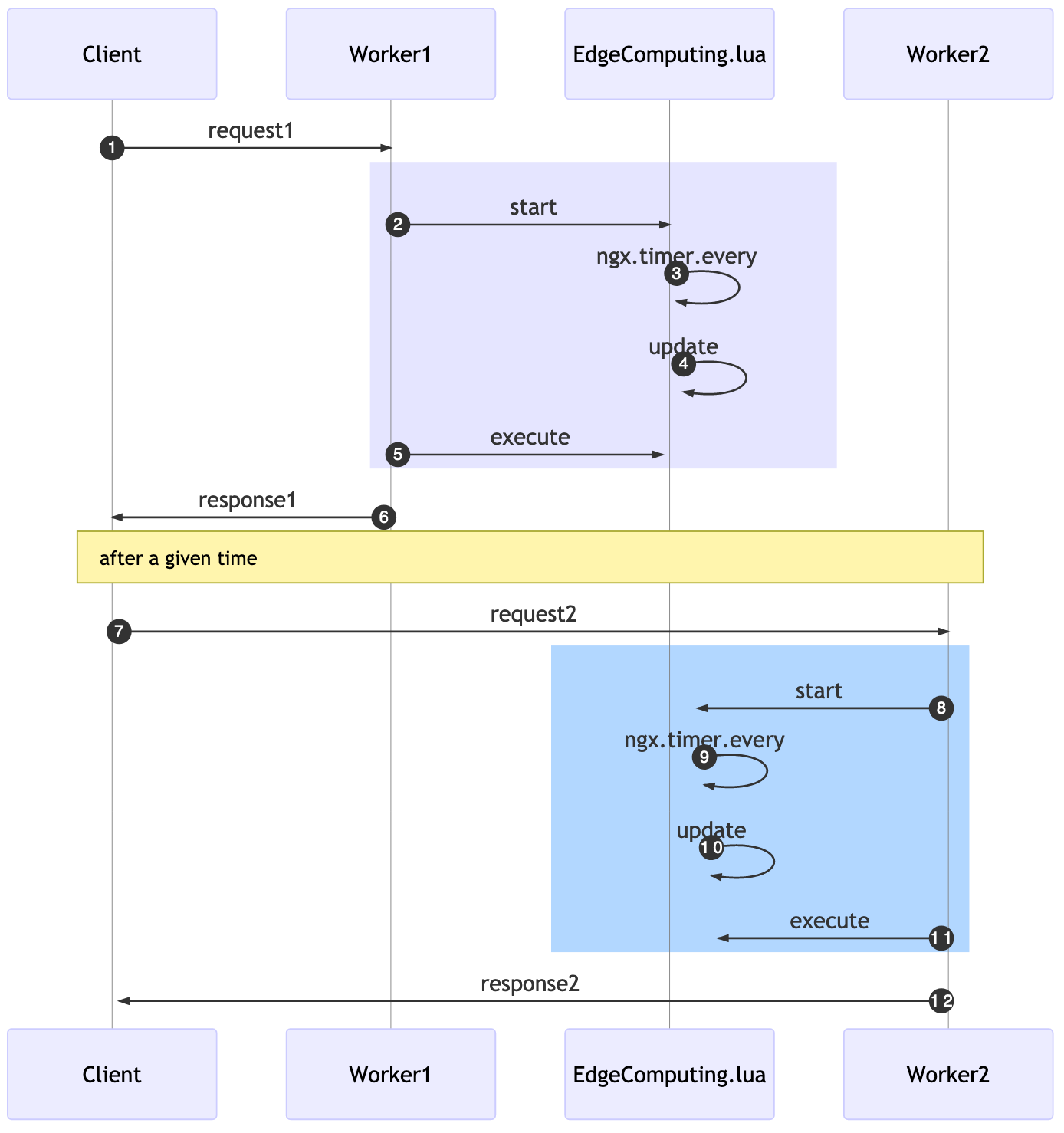
A funny behavior will happen, related to the eventual consistency nature of this solution: if a client issues a request1, in a given time for a Worker1, later the same user does another request2 and a different Worker2 will accept it. The time in which each worker will run the update function will be different.
This means that the effective deployment of your CUs will be different even within a single server. The practical consequence for this is that the server might answer something different for a worker in comparison to another one. It will eventually be consistent given the x seconds delay declared as update interval.
Nginx worker load balancing relies on the event-based model and OS-dependent mechanisms to efficiently distribute requests among worker processes.
How to use it
Adding the CU via the Redis cluster will make it work.
Computing Edge Use Cases
Let’s list some of the possible usages for this platform so we can think a little bit ahead of time.
- access control – tokens, access control, origin
- change response
- decorate headers
- generate content
- traffic redirect
- advanced caching
- …
The options are endless, but let’s try to summarize the features that we didn’t add to the code yet.
When we implemented the request counter we used redis as our data store so it’s safe to assume that somehow the CUs might use redis to persist data. Another thing we could do is to offer sampling, instead of executing the task for all requests we could run it for 3% of the them.
Another feature we could do is to allow filtering by the host. In this case, we want a given CU to execute in a specific set of machines only, but we also can achieve that in the CU itself if we need to.
The persistence needs to be passed for the CU, we can achieve that by wrapping the provided raw string code with a function that receives an input and pass this argument through the pcall call.
We’ll have access to the edge_computing in our CUs as if it was a global variable.
And finally, we can mimic the sampling technique by using a random function. Let’s say we want a given CU to be executed 50% of the time.
We need to encode the desired state at the datastore level and before we run the CU, we check if the random number, ranging from 1 to 100, is smaller or equal to the desired sampling rate.
Pure random distribution is not the most adequate, maybe in the future, we can use an algorithm similar to the power of two choices.
Future
Any platform is a complex piece of software that needs to be flexible, accommodate many kinds of usage, be easy to use, be safe and it still needs to be open for future innovation/changes such as:
- a control plane where you can create CUs using UI
- if the execution order is important then change the current data types
- add usage metrics per CU
- wrapper the execution with a timeout/circuit breaker mechanism
I hope you enjoyed these blog posts, they were meant to mostly show some trade-offs and also to deepen the nginx and Lua knowledge.




{kind=link}
You must be logged in to post a comment.