At the last Globo.com’s hackathon, Lucas Costa and I built a simple Lua library to provide a distributed rate measurement system that depends on Redis and run embedded in Nginx but before we explain what we did let’s start by understanding the problem that a throttling system tries to solve and some possible solutions.
Suppose we just built an API but some users are doing too many requests abusing their request quota, how can we deal with them? Nginx has a rate limiting feature that is easy to use:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| events { | |
| worker_connections 1024; | |
| } | |
| error_log stderr; | |
| http { | |
| limit_req_zone $binary_remote_addr zone=mylimit:10m rate=1r/m; | |
| server { | |
| listen 8080; | |
| location /api0 { | |
| default_type 'text/plain'; | |
| limit_req zone=mylimit; | |
| content_by_lua_block { | |
| ngx.say("hello world") | |
| } | |
| } | |
| } | |
| } |
This nginx configuration creates a zone called mylimit that limits a user, based on its IP, to be able to only do a single request per minute. To test this, save this config file as nginx.conf and run the command:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| docker run –rm -p 8080:8080 \ | |
| -v $(pwd)/nginx.conf:/usr/local/openresty/nginx/conf/nginx.conf \ | |
| openresty/openresty:alpine |
We can use curl to test its effectiveness:
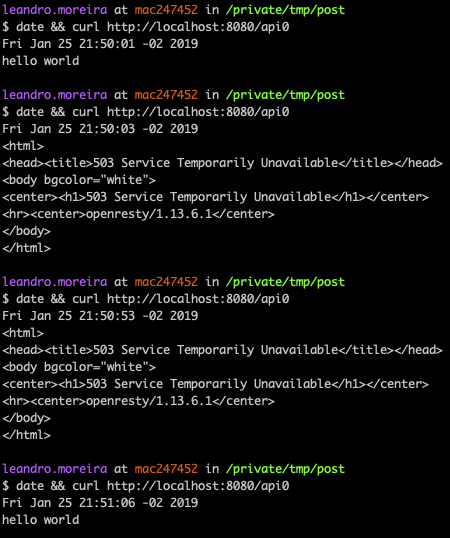
As you can see, our first request was just fine, right at the start of the minute 50, but then our next two requests failed because we were restricted by the nginx limit_req directive that we setup to accept only 1 request per minute. In the next minute we received a successful response.
This approach has a problem though, for instance, a user could use multiple cloud VM’s and then bypass the limit by IP. Let’s instead use the user token argument:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| events { | |
| worker_connections 1024; | |
| } | |
| error_log stderr; | |
| http { | |
| limit_req_zone $arg_token zone=mylimit:10m rate=1r/m; | |
| server { | |
| listen 8080; | |
| location /api0 { | |
| default_type 'text/plain'; | |
| limit_req zone=mylimit; | |
| content_by_lua_block { | |
| ngx.say("hello world") | |
| } | |
| } | |
| } | |
| } | |
There is another good reason to avoid this limit by IP approach, many of your users can be behind a single IP and by rate limiting them based on their IP, you might be blocking some legit uses.
Now a user can’t bypass by using multiple IPs, its token is used as a key to the limit rate counter.
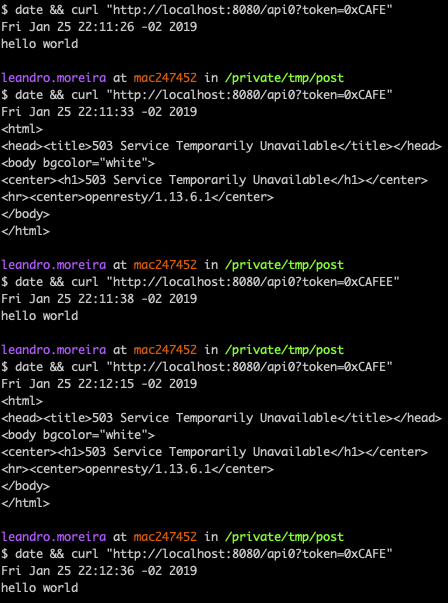
You can even notice that once a new user requests the same API, the user with token=0xCAFEE, the server replies with success.
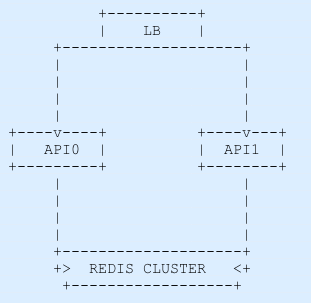
Since our API is so useful, more and more users are becoming paid members and now we need to scale it out. What we can do is to put a load balancer in front of two instances of our API. To act as LB we can still use nginx, here’s a simple (workable) version of the required config.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| events { | |
| worker_connections 1024; | |
| } | |
| error_log stderr; | |
| http { | |
| upstream app { | |
| server nginx1:8080; | |
| server nginx2:8080; | |
| } | |
| server { | |
| listen 8080; | |
| location /api0 { | |
| proxy_pass http://app; | |
| } | |
| } | |
| } |
Now to simulate our scenario we need to use multiple containers, let’s use docker-compose to this task, the config file just declare three services, two acting as our API and the LB.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| version: '3' | |
| services: | |
| nginxlb: | |
| image: openresty/openresty:alpine | |
| volumes: | |
| – "./lbnginx.conf:/usr/local/openresty/nginx/conf/nginx.conf" | |
| ports: | |
| – "8080:8080" | |
| nginx1: | |
| image: openresty/openresty:alpine | |
| volumes: | |
| – "./nginx.conf:/usr/local/openresty/nginx/conf/nginx.conf" | |
| ports: | |
| – "8080" | |
| nginx2: | |
| image: openresty/openresty:alpine | |
| volumes: | |
| – "./nginx.conf:/usr/local/openresty/nginx/conf/nginx.conf" | |
| ports: | |
| – "8080" |
Run the command docker-compose up and then in another terminal tab simulate multiple requests.
When we request http://localhost:8080 we’re hitting the lb instance.

It’s weird?! Now our limit system is not working, or at least not properly. The first request was a 200, as expected, but the next one was also a 200.
It turns out that the LB needs a way to forward the requests to one of the two APIs instances, the default algorithm that our LB is using is the round-robin which distributes the requests each time for a server going in the list of servers as a clock.
The Nginx limit_req stores its counters on the node’s memory, that’s why our first two requests were successful.
And if we save our counters on a data store? We could use redis, it’s in memory and is pretty fast.
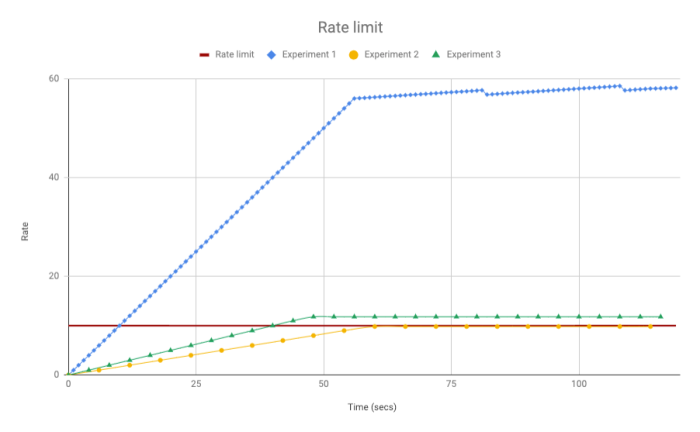
But how are we going to build this counting/rating system? This can be solved using a histogram to get the average, a leaky bucket algorithm or a simplified sliding window proposed by Cloudflare.
To implement the sliding window algorithm it’s actually very easy, you will keep two counters, one for the last-minute and one for the current minute and then you can calculate the current rate by factoring the two minutes counters as if they were in a perfectly constant rate.
To make things easier, let’s debug an example of this algorithm in action. Let’s say our throttling system allows 10 requests per minute and that our past minute counter for a token is 6 and the current minute counter is 1 and we are at the second 10.
last_counter * ((60 – current_second) / 60) + current_counter
6 * ((60 – 10) / 60) + 1 = 6 # the current rate is 6 which is under 10 req/m
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| — redis_client is an instance of a redis_client | |
| — key is the limit parameter, in this case ngx.var.arg_token | |
| redis_rate.measure = function(redis_client, key) | |
| local current_time = math.floor(ngx.now()) | |
| local current_minute = math.floor(current_time / 60) % 60 | |
| local past_minute = current_minute – 1 | |
| local current_key = key .. current_minute | |
| local past_key = key .. past_minute | |
| local resp, err = redis_client:get(past_key) | |
| local last_counter = tonumber(resp) | |
| resp, err = redis_client:incr(current_key) | |
| local current_counter = tonumber(resp) – 1 | |
| resp, err = redis_client:expire(current_key, 2 * 60) | |
| local current_rate = last_counter * ((60 – (current_time % 60)) / 60) + current_counter | |
| return current_rate, nil | |
| end | |
| return redis_rate |
To store the counters we used three simple (O(1)) redis operations:
- GET to retrieve the last counter
- INCR to count the current counter and retrieve its current value.
- EXPIRE to set an expiration for the current counter, since it won’t be useful after two minutes.
We decided to not use MULTI operation therefore in theory some really small percentage of the users can be wrongly allowed, one of the reasons to dismiss the MULTI operation was because we use a lua driver redis cluster without support but we use pipeline and hash tags to save 2 extra round trips.
Now it’s the time to integrate the lua rate sliding window algorithm into nginx.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| http { | |
| server { | |
| listen 8080; | |
| location /lua_content { | |
| default_type 'text/plain'; | |
| content_by_lua_block { | |
| local redis_client = redis_cluster:new(config) | |
| local rate, err = redis_rate.measure(redis_client, ngx.var.arg_token) | |
| if err then | |
| ngx.log(ngx.ERR, "err: ", err) | |
| ngx.exit(ngx.HTTP_INTERNAL_SERVER_ERROR) | |
| end | |
| if rate > 10 then | |
| ngx.exit(ngx.HTTP_FORBIDDEN) | |
| end | |
| ngx.say(rate) | |
| } | |
| } | |
| } | |
| } |
You probably want to use the access_by_lua phase instead of the content_by_lua from the nginx cycle.
The nginx configuration is uncomplicated to understand, it uses the argument token as the key and if the rate is above 10 req/m we just reply with 403. Simple solutions are usually elegant and can be scalable and good enough.
The lua library and this complete example is at Github and you can run it locally and test it without great effort.

[…] How to build a distributed throttling system with Nginx + Lua + Redis: 15 mins read. This post covers how to build API rate limiting system with Nginx, Lua, and Redis. Instructions mentioned in the post are clear and to the point. […]
[…] A distributed rate counting system with Lua and Redis 2 by dreampeppers99 | 0 comments on Hacker News. […]
[…] A distributed rate counting system with Lua and Redis 2 by dreampeppers99 | 0 comments on Hacker News. […]
[…] A distributed rate counting system with Lua and Redis 2 by dreampeppers99 | 0 comments on Hacker News. […]
[…] A distributed rate counting system with Lua and Redis 2 by dreampeppers99 | 0 comments on Hacker News. […]
[…] A distributed rate counting system with Lua and Redis 2 by dreampeppers99 | 0 comments on Hacker News. […]
[…] A distributed rate counting system with Lua and Redis 6 by dreampeppers99 | 0 comments on Hacker News. […]
[…] Source: leandromoreira.com.br […]
[…] A distributed rate counting system with Lua and Redis […]
[…] https://leandromoreira.com.br/2019/01/25/how-to-build-a-distributed-throttling-system-with-nginx-lua… […]
[…] Source: leandromoreira.com.br […]
[…] A distributed rate counting system with Lua and RedisAt the last Globo.com’s hackathon, Lucas Costa and I built a simple Lua library to provide a distributed rate measurement system that depends on Redis and run embedded in Nginx but before we ⦠[…]
Hi, can you just set the limit_req in lbnginx.conf instead of nginx.conf? Then I think you don’t need the lua script. What do you think?
I think you still need Redis + Lua. The idea is that if you have tens of Nginx’s, each one of them will only limit req based on their context (aka their memory). The need to use Redis/lua is to allow you to have hundreds of Nginx’s and they will limit as if they were one, regardless which one you trying to request.
But you’re right if our only entry point as the lbnginx. 🙂
This library/idea is really needed when have either multiple load balancers or a load balancer where you can’t act on http (l7) level.
I got it. Thanks for your response and great article. I got one more question.
Is it possible to set the remaining count for limit_req in X-RateLimit-Remaining header?
I want to report the current state of the rate limit for a request through the response header. So the client can have an idea about how many limits are left or how long it needs to wait before it tries again.
For example, in the following config, I wonder if I can use the lua script to add headers like X-RateLimit-Limit, X-RateLimit-Remaining, X-RateLimit-Reset, or Retry-After. I couldn’t find nginx provides such data out-of-box.
http {
limit_req_zone $binary_remote_addr zone=login:10m rate=5r/s;
limit_req_status 429;
server {
listen 80;
server_name [removed];
location / {
limit_req zone=limit burst=5;
proxy_pass http://reverse-proxy-example;
add_header X-RateLimit-Remaining [nginx variable?];
add_header X-RateLimit-Reset [nginx variable?]
}
}